Table of contents:
Konsep Data Mining: Menggali Harta Karun Data merupakan proses menarik informasi berharga dari kumpulan data besar. Bayangkan memiliki tambang emas yang penuh data mentah, Data Mining adalah alat untuk mengolahnya menjadi informasi berharga yang dapat digunakan untuk pengambilan keputusan yang lebih baik. Dari prediksi tren pasar hingga deteksi penyakit, Data Mining berperan penting dalam berbagai sektor.
Data Mining melibatkan berbagai teknik untuk menemukan pola, tren, dan hubungan yang tersembunyi dalam data. Proses ini tidak hanya sekedar mengumpulkan data, tetapi juga membersihkan, mengubah, menganalisis, dan menginterpretasi data tersebut untuk menghasilkan wawasan yang berguna. Pemahaman tentang konsep Data Mining sangat penting bagi siapa saja yang ingin memanfaatkan kekuatan data dalam era digital saat ini.
Definisi Data Mining
Data mining, atau penambangan data, merupakan proses penggalian informasi berharga dan pola-pola tersembunyi dari kumpulan data yang besar dan kompleks. Proses ini memanfaatkan berbagai teknik statistik, matematika, dan informatika untuk menemukan pengetahuan yang sebelumnya tidak diketahui, yang dapat digunakan untuk pengambilan keputusan yang lebih baik dan pemahaman yang lebih mendalam terhadap suatu fenomena.
Data mining berbeda dengan kegiatan pengolahan data lainnya seperti pengumpulan data atau pelaporan data. Pengumpulan data fokus pada akuisisi data mentah, sedangkan pelaporan data hanya menyajikan data yang sudah ada dalam bentuk yang terstruktur. Data mining melangkah lebih jauh dengan melakukan analisis mendalam untuk menemukan pola, tren, dan anomali yang tidak terlihat secara langsung.
Tujuan Penerapan Data Mining
Tujuan utama penerapan data mining adalah untuk menemukan pengetahuan yang berguna dan dapat ditindaklanjuti dari data yang tersedia. Penemuan ini dapat digunakan untuk berbagai tujuan, mulai dari meningkatkan efisiensi operasional hingga pengembangan produk dan layanan baru. Secara umum, data mining bertujuan untuk:
- Meningkatkan pemahaman terhadap data.
- Mengidentifikasi tren dan pola.
- Memprediksi kejadian masa depan.
- Mengoptimalkan proses bisnis.
- Mendukung pengambilan keputusan yang lebih baik.
Contoh Kasus Penerapan Data Mining
Data mining telah diaplikasikan secara luas di berbagai bidang, memberikan dampak signifikan terhadap efisiensi dan inovasi. Berikut beberapa contohnya:
- Kesehatan: Data mining digunakan untuk memprediksi risiko penyakit berdasarkan riwayat medis pasien, menganalisis penyebaran penyakit menular, dan mengoptimalkan perawatan pasien. Misalnya, analisis data pasien dengan penyakit jantung dapat mengidentifikasi faktor risiko yang sebelumnya tidak diketahui, sehingga memungkinkan intervensi lebih dini dan pencegahan yang lebih efektif.
- Bisnis: Perusahaan menggunakan data mining untuk menganalisis perilaku konsumen, memprediksi penjualan, dan menargetkan pemasaran yang lebih efektif. Sebagai contoh, ritel online dapat menggunakan data mining untuk merekomendasikan produk kepada pelanggan berdasarkan riwayat pembelian dan preferensi mereka. Analisis data transaksi juga dapat membantu mengidentifikasi pelanggan yang berpotensi meninggalkan perusahaan (churn prediction).
- Teknologi: Dalam teknologi, data mining digunakan untuk mendeteksi kecurangan, meningkatkan keamanan sistem, dan mengembangkan sistem rekomendasi yang lebih cerdas. Misalnya, deteksi intrusi pada jaringan komputer dapat dilakukan dengan menganalisis pola lalu lintas jaringan yang mencurigakan.
Perbandingan Teknik Data Mining
Berbagai teknik data mining tersedia, masing-masing dengan kekuatan dan kelemahannya sendiri. Pilihan teknik yang tepat bergantung pada jenis data dan tujuan analisis.
| Teknik | Deskripsi Singkat | Kegunaan | Contoh Penerapan |
|---|---|---|---|
| Klasifikasi | Menggolongkan data ke dalam kategori tertentu. | Prediksi, pengelompokan | Deteksi spam email, diagnosa penyakit |
| Regresi | Memprediksi nilai numerik berdasarkan variabel lain. | Prediksi kuantitatif | Prediksi penjualan, peramalan harga saham |
| Clustering | Mengelompokkan data berdasarkan kesamaan karakteristik. | Segmentasi pasar, analisis kelompok | Pengelompokan pelanggan, analisis gen |
| Association Rule Mining | Menemukan hubungan antara item dalam suatu dataset. | Analisis keranjang belanja | Rekomendasi produk, analisis tren pembelian |
Langkah-Langkah Umum dalam Proses Data Mining
Proses data mining umumnya melibatkan beberapa langkah kunci yang saling berkaitan. Tahapan ini memastikan bahwa analisis data dilakukan secara sistematis dan menghasilkan hasil yang akurat dan bermakna.
- Pengumpulan Data: Mengumpulkan data dari berbagai sumber.
- Pembersihan Data (Data Cleaning): Menghapus data yang tidak valid, menangani data yang hilang, dan mentransformasikan data ke dalam format yang sesuai.
- Transformasi Data: Mengubah data ke dalam format yang cocok untuk analisis.
- Pemilihan Data (Data Selection): Memilih subset data yang relevan untuk analisis.
- Data Mining: Menerapkan algoritma data mining untuk menemukan pola dan pengetahuan.
- Evaluasi Pola: Mengevaluasi pola yang ditemukan untuk memastikan akurasi dan kegunaan.
- Visualisasi dan Interpretasi: Memvisualisasikan pola yang ditemukan dan menginterpretasikan hasilnya.
Teknik-Teknik Data Mining
Data mining melibatkan beragam teknik untuk mengekstrak informasi berharga dari kumpulan data besar. Pemahaman mendalam tentang teknik-teknik ini krusial untuk menerapkan data mining secara efektif dan mencapai hasil yang diinginkan. Berikut ini beberapa teknik data mining yang umum digunakan, beserta penjelasan dan contoh penerapannya.
Teknik Data Mining Berbasis Aturan Asosiasi
Teknik ini bertujuan menemukan hubungan atau pola asosiasi antara item-item dalam suatu dataset. Algoritma yang paling terkenal adalah Apriori dan FP-Growth. Kedua algoritma ini bekerja dengan menghitung frekuensi kemunculan item-item dan mengidentifikasi aturan asosiasi yang memenuhi ambang batas tertentu, seperti support dan confidence.
- Apriori: Algoritma ini menggunakan pendekatan bottom-up untuk menemukan itemset frequent, secara bertahap membangun itemset yang lebih besar dari itemset yang lebih kecil.
- FP-Growth: Algoritma ini menggunakan struktur data yang disebut Frequent Pattern Tree (FP-Tree) untuk meningkatkan efisiensi pencarian itemset frequent.
Contoh penerapannya adalah dalam analisis keranjang belanja di supermarket. Dengan menganalisis transaksi penjualan, kita dapat menemukan aturan asosiasi seperti “jika pelanggan membeli susu dan roti, maka kemungkinan besar mereka juga akan membeli telur”. Informasi ini sangat berguna untuk strategi penempatan produk di rak dan promosi penjualan.
Teknik Pengelompokan (Clustering)
Clustering adalah teknik untuk mengelompokkan data berdasarkan kesamaan karakteristik. Data yang memiliki kemiripan akan dikelompokkan ke dalam satu cluster, sementara data yang berbeda akan berada di cluster yang berbeda. Beberapa algoritma clustering yang populer antara lain K-Means, Hierarchical Clustering, dan DBSCAN.
- K-Means: Algoritma ini mengelompokkan data ke dalam K cluster dengan meminimalkan jarak antara titik data dan centroid clusternya. Jumlah cluster (K) harus ditentukan terlebih dahulu.
- Hierarchical Clustering: Algoritma ini membangun hirarki cluster, dimulai dari setiap titik data sebagai cluster tunggal, kemudian secara bertahap menggabungkan cluster yang paling mirip hingga terbentuk satu cluster besar.
- DBSCAN: Algoritma ini mengelompokkan data berdasarkan kepadatan titik data. Titik data yang berada di daerah yang padat akan dikelompokkan bersama, sementara titik data yang terisolasi akan diklasifikasikan sebagai noise.
Contoh penerapan clustering adalah dalam segmentasi pelanggan. Dengan mengelompokkan pelanggan berdasarkan perilaku pembelian, demografi, atau preferensi, perusahaan dapat mengembangkan strategi pemasaran yang lebih tertarget.
Teknik Klasifikasi
Klasifikasi bertujuan untuk memprediksi kelas atau kategori dari suatu data berdasarkan karakteristiknya. Algoritma klasifikasi mempelajari pola dari data pelatihan untuk membangun model prediksi. Contoh algoritma klasifikasi yang sering digunakan antara lain Naïve Bayes, Decision Tree, Support Vector Machine (SVM), dan K-Nearest Neighbors (KNN).
- Naïve Bayes: Algoritma ini berdasarkan teorema Bayes, yang mengasumsikan kemerdekaan antar fitur.
- Decision Tree: Algoritma ini membangun pohon keputusan untuk mengklasifikasikan data berdasarkan serangkaian aturan.
- Support Vector Machine (SVM): Algoritma ini mencari hyperplane yang optimal untuk memisahkan data dari kelas yang berbeda.
- K-Nearest Neighbors (KNN): Algoritma ini mengklasifikasikan data berdasarkan kelas dari K tetangga terdekatnya.
Contoh penerapan klasifikasi adalah dalam deteksi spam email. Model klasifikasi dilatih dengan data email yang telah diberi label sebagai spam atau non-spam, kemudian digunakan untuk memprediksi apakah email baru merupakan spam atau bukan.
Perbedaan Supervised dan Unsupervised Learning
Supervised learning menggunakan data pelatihan yang telah diberi label untuk membangun model prediksi, sementara unsupervised learning menggunakan data tanpa label untuk menemukan pola dan struktur dalam data. Klasifikasi dan regresi termasuk dalam supervised learning, sedangkan clustering termasuk dalam unsupervised learning. Supervised learning bertujuan untuk memprediksi output, sedangkan unsupervised learning bertujuan untuk menemukan struktur tersembunyi dalam data.
Teknik Regresi
Regresi merupakan teknik yang digunakan untuk memodelkan hubungan antara variabel dependen dan satu atau lebih variabel independen. Kelebihannya adalah kemampuannya untuk memprediksi nilai numerik dari variabel dependen berdasarkan nilai variabel independen. Namun, regresi sensitif terhadap outlier dan asumsi linearitas, serta mungkin sulit untuk menafsirkan model yang kompleks.
Tahapan Proses Data Mining
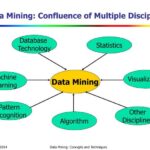
Proses data mining bukanlah pekerjaan yang sederhana. Ia melibatkan serangkaian langkah sistematis untuk menggali informasi berharga dari kumpulan data yang besar dan kompleks. Memahami tahapan-tahapan ini krusial untuk memastikan keberhasilan proyek data mining. Proses ini, meskipun tampak linear, seringkali bersifat iteratif, artinya mungkin perlu kembali ke tahap sebelumnya untuk melakukan penyesuaian atau perbaikan.
Tahapan Penting dalam Proses Data Mining
Secara umum, proses data mining dapat dibagi menjadi beberapa tahapan utama. Setiap tahapan memiliki perannya masing-masing dan saling berkaitan erat. Kegagalan pada satu tahap dapat mempengaruhi kualitas hasil pada tahap selanjutnya.
- Pengumpulan Data: Tahap awal ini berfokus pada pengumpulan data dari berbagai sumber, baik internal maupun eksternal. Sumber data bisa berupa database relasional, file teks, sensor, media sosial, dan lain sebagainya. Kualitas data yang dikumpulkan sangat menentukan kualitas hasil data mining.
- Pembersihan Data (Data Cleaning): Tahap ini bertujuan untuk menangani data yang tidak konsisten, hilang, atau salah. Proses ini mencakup penghapusan data duplikat, penanganan nilai yang hilang (misalnya dengan imputasi atau penghapusan), dan koreksi kesalahan data. Data yang bersih dan akurat merupakan fondasi penting untuk analisis yang handal.
- Transformasi Data: Setelah dibersihkan, data mungkin perlu ditransformasikan agar sesuai dengan algoritma data mining yang akan digunakan. Transformasi ini bisa berupa normalisasi data, reduksi dimensi, atau pengubahan tipe data. Tujuannya adalah untuk meningkatkan kinerja algoritma dan mempermudah interpretasi hasil.
- Pemilihan Model dan Algoritma: Tahap ini melibatkan pemilihan algoritma data mining yang tepat berdasarkan tujuan analisis dan karakteristik data. Terdapat berbagai algoritma, seperti klasifikasi, regresi, pengelompokan (clustering), dan asosiasi, masing-masing dengan kelebihan dan kekurangannya.
- Pelatihan Model dan Analisis: Algoritma yang terpilih kemudian dilatih menggunakan data yang telah disiapkan. Proses ini menghasilkan model yang dapat digunakan untuk memprediksi atau mengklasifikasikan data baru. Analisis hasil pelatihan penting untuk mengevaluasi performa model.
- Evaluasi Hasil: Tahap terakhir ini melibatkan evaluasi kinerja model yang telah dibangun. Metrik evaluasi yang digunakan bergantung pada jenis algoritma dan tujuan analisis. Evaluasi ini membantu memastikan bahwa model memberikan hasil yang akurat dan dapat diandalkan.
Pentingnya Pembersihan Data (Data Cleaning)
Pembersihan data merupakan langkah kritis dalam proses data mining. Data yang kotor atau tidak akurat dapat menghasilkan model yang bias dan memberikan hasil yang menyesatkan. Proses ini melibatkan identifikasi dan penanganan berbagai masalah data, seperti nilai yang hilang, data outlier, dan inkonsistensi data. Teknik yang digunakan bisa berupa imputasi (penggantian nilai yang hilang), smoothing (pengurangan noise), dan penghapusan data yang tidak valid.
Transformasi Data untuk Persiapan Data Mining
Transformasi data bertujuan untuk mengubah data mentah menjadi format yang sesuai untuk algoritma data mining. Proses ini bisa melibatkan berbagai teknik, seperti:
- Normalisasi: Mengubah skala data agar semua atribut memiliki rentang nilai yang sama, sehingga mencegah atribut dengan skala lebih besar mendominasi proses analisis.
- Standarisasi: Mengubah data agar memiliki rata-rata 0 dan standar deviasi 1.
- Reduksi Dimensi: Mengurangi jumlah atribut tanpa kehilangan informasi penting. Teknik ini berguna untuk menangani data berdimensi tinggi.
- Pengubahan Tipe Data: Mengubah tipe data (misalnya dari teks menjadi numerik) agar sesuai dengan kebutuhan algoritma.
Diagram Alur Tahapan Proses Data Mining
Berikut gambaran diagram alur proses data mining:
[Diagram alur: Mulai -> Pengumpulan Data -> Pembersihan Data -> Transformasi Data -> Pemilihan Model -> Pelatihan Model -> Evaluasi Hasil -> Akhir. Panah menghubungkan setiap tahap secara berurutan. Bentuk kotak persegi panjang untuk setiap tahap, bentuk diamond untuk keputusan/evaluasi]
Tantangan dan Solusi dalam Setiap Tahapan Data Mining
Proses data mining seringkali dihadapkan pada berbagai tantangan. Memahami tantangan ini dan solusi yang mungkin sangat penting untuk keberhasilan proyek.
| Tahapan | Tantangan | Solusi | Contoh |
|---|---|---|---|
| Pengumpulan Data | Data tidak lengkap, tersebar di berbagai sumber, kualitas data buruk | Integrasi data, pembersihan data, validasi data | Menggabungkan data penjualan dari berbagai cabang toko, membersihkan data yang salah ketik |
| Pembersihan Data | Data hilang, outlier, inkonsistensi | Imputasi, smoothing, penghapusan data | Mengganti nilai penjualan yang hilang dengan rata-rata penjualan, menghapus data penjualan yang jauh di luar jangkauan normal |
| Transformasi Data | Data tidak ternormalisasi, dimensi tinggi | Normalisasi, standarisasi, reduksi dimensi | Menormalisasi data penjualan agar berkisar antara 0 dan 1, menggunakan PCA untuk mengurangi dimensi data |
| Pemilihan Model | Memilih algoritma yang tepat | Eksperimen dengan berbagai algoritma, evaluasi kinerja | Mencoba algoritma Naive Bayes dan SVM untuk klasifikasi, membandingkan akurasi dan presisi |
| Pelatihan Model | Overfitting, underfitting | Pengaturan parameter yang tepat, validasi silang | Menyesuaikan parameter regularisasi untuk mencegah overfitting, menggunakan teknik validasi silang untuk mengevaluasi kinerja model pada data yang belum pernah dilihat |
| Evaluasi Hasil | Interpretasi hasil yang sulit | Visualisasi data, metrik evaluasi yang tepat | Menggunakan grafik untuk memvisualisasikan hasil klasifikasi, menggunakan metrik seperti precision dan recall untuk mengevaluasi kinerja model |
Penerapan Data Mining
Data mining, dengan kemampuannya mengolah data mentah menjadi informasi berharga, memiliki penerapan luas di berbagai sektor. Kemampuannya untuk mengidentifikasi pola, tren, dan anomali membuka peluang besar untuk pengambilan keputusan yang lebih baik dan peningkatan efisiensi. Berikut beberapa contoh penerapan data mining di berbagai industri.
Studi Kasus Data Mining di Pemasaran
Sebuah perusahaan ritel besar menggunakan data mining untuk memprediksi perilaku konsumen dan mengoptimalkan kampanye pemasarannya. Prosesnya dimulai dengan pengumpulan data transaksi pelanggan, data demografis, dan riwayat interaksi dengan perusahaan (misalnya, kunjungan website, email marketing). Data ini kemudian dibersihkan dan diolah menggunakan algoritma seperti clustering dan association rule mining. Clustering membantu mengelompokkan pelanggan berdasarkan kesamaan perilaku pembelian, sementara association rule mining mengidentifikasi hubungan antara produk yang sering dibeli bersama.
Hasilnya, perusahaan dapat menargetkan kampanye pemasaran yang lebih efektif, misalnya dengan menawarkan diskon khusus untuk produk yang sering dibeli bersama oleh segmen pelanggan tertentu. Hal ini berujung pada peningkatan penjualan dan kepuasan pelanggan.
Aplikasi Data Mining di Industri Kesehatan
Data mining menawarkan beragam manfaat dalam industri kesehatan. Penggunaannya dapat meningkatkan kualitas perawatan pasien dan efisiensi operasional rumah sakit.
- Prediksi penyakit: Mengidentifikasi faktor risiko dan memprediksi kemungkinan seseorang terkena penyakit tertentu berdasarkan riwayat medis dan gaya hidup.
- Personalisasi pengobatan: Menganalisis data genetik dan medis pasien untuk menentukan pengobatan yang paling efektif dan aman.
- Deteksi penipuan asuransi: Mengidentifikasi klaim asuransi yang mencurigakan dan mencegah penipuan.
- Pemantauan kualitas perawatan: Menganalisis data pasien untuk mengidentifikasi area yang perlu ditingkatkan dalam perawatan kesehatan.
Potensi dan Tantangan Data Mining di Sektor Keuangan
Sektor keuangan sangat bergantung pada data. Data mining berperan penting dalam pengelolaan risiko, deteksi penipuan, dan pengembangan produk keuangan. Potensinya meliputi prediksi risiko kredit, deteksi pencucian uang, dan personalisasi layanan keuangan. Namun, tantangannya meliputi keamanan data, regulasi kepatuhan, dan kompleksitas data keuangan yang besar dan beragam.
Penerapan Data Mining untuk Meningkatkan Efisiensi Operasional di Perusahaan Manufaktur, Konsep data mining
Sebuah perusahaan manufaktur dapat menggunakan data mining untuk meningkatkan efisiensi operasionalnya dengan menganalisis data produksi, seperti waktu siklus produksi, tingkat kerusakan mesin, dan persediaan bahan baku. Dengan menganalisis data ini, perusahaan dapat mengidentifikasi hambatan produksi, memprediksi potensi masalah, dan mengoptimalkan proses produksi. Misalnya, data mining dapat mengidentifikasi pola kerusakan mesin tertentu yang terjadi pada waktu dan kondisi operasi tertentu, sehingga perusahaan dapat melakukan perawatan prediktif dan mencegah downtime yang tidak terduga.
Selain itu, data mining dapat membantu mengoptimalkan tingkat persediaan bahan baku, mengurangi biaya penyimpanan, dan mencegah kekurangan bahan baku yang dapat mengganggu produksi.
Penerapan data mining, meskipun menawarkan banyak manfaat, menimbulkan implikasi etika yang signifikan, terutama terkait privasi data. Penggunaan data pribadi harus dilakukan secara bertanggung jawab dan transparan, dengan perlindungan yang memadai terhadap potensi penyalahgunaan data. Regulasi yang ketat dan kesadaran etika sangat penting untuk memastikan penerapan data mining yang bertanggung jawab dan etis.
Perangkat Lunak dan Alat Data Mining

Data mining, sebagai proses penggalian informasi berharga dari kumpulan data besar, sangat bergantung pada perangkat lunak dan alat yang tepat. Pilihan perangkat lunak yang tepat akan sangat memengaruhi efisiensi dan akurasi hasil analisis. Oleh karena itu, memahami berbagai pilihan dan fitur yang ditawarkan sangatlah penting.
Perangkat Lunak Data Mining Populer
Berbagai perangkat lunak data mining tersedia, masing-masing dengan kekuatan dan kelemahannya sendiri. Beberapa yang populer meliputi Weka, RapidMiner, KNIME, dan SPSS Modeler. Perangkat lunak ini menawarkan berbagai algoritma data mining, fasilitas visualisasi data, dan kemampuan pemrosesan data yang handal. Selain perangkat lunak berbayar, terdapat pula pilihan open-source yang handal.
Perbandingan Fitur dan Keunggulan Perangkat Lunak Data Mining
Perbandingan antar perangkat lunak data mining seringkali bergantung pada kebutuhan spesifik pengguna. Weka, misalnya, dikenal karena antarmuka yang mudah digunakan dan koleksi algoritma yang luas, ideal untuk pembelajaran dan eksplorasi data. RapidMiner menawarkan pendekatan yang lebih visual dan berbasis alur kerja (workflow), cocok untuk membangun dan mengotomatiskan proses data mining yang kompleks. KNIME, dengan pendekatan serupa, juga menawarkan fleksibilitas tinggi dan integrasi yang baik dengan berbagai sumber data.
SPSS Modeler, sebagai perangkat lunak komersial, umumnya memiliki fitur yang lebih canggih dan dukungan teknis yang lebih komprehensif.
Memilih Perangkat Lunak Data Mining yang Tepat
Pemilihan perangkat lunak data mining yang tepat bergantung pada beberapa faktor kunci, termasuk ukuran dan jenis data, keahlian pengguna, anggaran, dan tujuan analisis. Untuk proyek kecil dengan data sederhana, Weka atau KNIME mungkin sudah cukup. Proyek yang lebih besar dan kompleks, dengan kebutuhan otomatisasi dan integrasi yang tinggi, mungkin lebih cocok menggunakan RapidMiner atau SPSS Modeler. Keahlian pengguna juga menjadi pertimbangan penting; perangkat lunak dengan antarmuka yang ramah pengguna akan lebih sesuai bagi pemula.
Tabel Perbandingan Spesifikasi Perangkat Lunak Data Mining
| Perangkat Lunak | Lisensi | Antarmuka | Keunggulan |
|---|---|---|---|
| Weka | Open Source | GUI berbasis Java | Mudah digunakan, koleksi algoritma luas |
| RapidMiner | Komersil (tersedia versi trial) | Visual, berbasis alur kerja | Otomatisasi, integrasi yang baik |
| KNIME | Open Source | Visual, berbasis alur kerja | Fleksibilitas tinggi, integrasi yang baik |
| SPSS Modeler | Komersil | GUI yang canggih | Fitur lengkap, dukungan teknis yang baik |
Library Pemrograman untuk Data Mining
Selain perangkat lunak khusus data mining, banyak library pemrograman yang menyediakan alat dan fungsi untuk melakukan analisis data. Python, misalnya, memiliki library seperti Scikit-learn yang menawarkan berbagai algoritma machine learning, termasuk klasifikasi, regresi, dan pengelompokan. Library ini menyediakan fungsi-fungsi yang efisien dan fleksibel untuk membangun model data mining yang kompleks. Library lain yang populer termasuk Pandas untuk manipulasi dan analisis data, dan Matplotlib serta Seaborn untuk visualisasi data.
Kesimpulan: Konsep Data Mining

Kesimpulannya, Konsep Data Mining menawarkan peluang luar biasa untuk mengungkap pengetahuan tersembunyi dalam data. Dengan pemahaman yang mendalam tentang teknik dan tahapannya, serta pertimbangan etika yang cermat, Data Mining dapat memberikan kontribusi signifikan bagi berbagai bidang. Kemajuan teknologi terus meningkatkan kemampuan Data Mining, membuka jalan bagi inovasi dan penemuan baru yang berdampak luas bagi kehidupan manusia.